商机详情 -
实时监测智慧运维平台批发
告警疲劳是运维团队的顽疾。智慧运维平台通过AI实现告警的智能降噪、压缩和路由。它能将同一根因产生的大量衍生告警合并为一条主事件;能根据告警的历史处理记录和学习运维人员的反馈,动态调整告警的优先级;还能根据值班表、技能标签和事件类型,将告警准确推送给较合适的处理人员,避免无关信息的干扰。这极大地提升了告警的有效性和可操作性,让每一次告警都成为有价值的行动指令,而非令人麻木的噪音。智慧运维平台的自动化能力不应是零散的脚本,而应是端到端的流程编排。例如,对于一个“磁盘空间告警”,自动化流程可以是:首先确认告警有效性 -> 自动登录服务器清理日志文件 -> 若清理后空间仍不足,则自动扩容磁盘 -> 更新CMDB配置信息 -> 较终关闭相关告警工单。平台通过图形化的流程设计器,将多个原子操作串联成一个完整的、可复用的自动化剧本,实现了复杂运维场景的“一键式”处置,明显提升了运营效率。智慧运维平台支持异常报警功能,可及时推送设备运行异常信息。实时监测智慧运维平台批发

可观测性(Observability)是智慧运维的基石,它超越了传统的监控概念,强调从系统外部输出(如日志、指标、追踪)中,能够理解和推断系统内部状态的能力。一个具备高度可观测性的平台,能够让我们不仅知道系统“出了什么问题”,更能理解“为什么会出问题”。它通过整合日志(Logging)记录离散事件、指标(Metrics)反映聚合状态、链路追踪(Tracing)描绘请求全景,构建了理解复杂分布式系统的三维数据模型。没有完善的可观测性数据基础,后续的AI分析与自动化就如同无源之水,智慧运维也就无从谈起。数据分析智慧运维平台批发该平台可实现数据中心运维流程的自动化,提升运维工作的效率与质量。
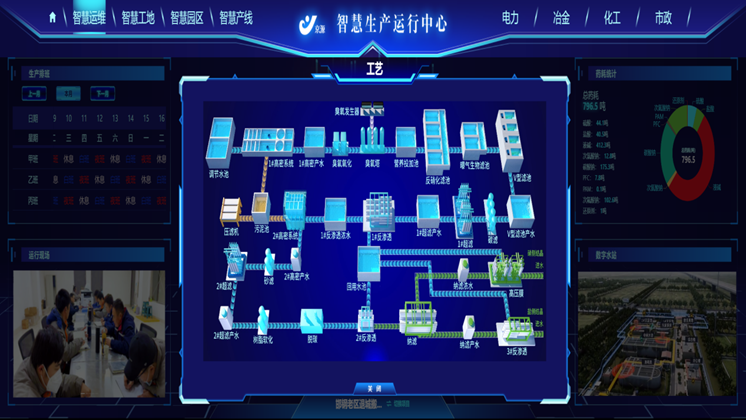
智慧运维平台对传统IT基础设施监控进行了整体智能化升级。它不仅能通过Agent和SNMP等手段采集CPU、内存、磁盘等基础指标,更能利用AI算法为每台服务器、网络设备建立个性化的性能基线。当资源使用率出现违背基线的异常波动时,即使未超过固定阈值,平台也能敏锐捕捉并告警。同时,平台能够关联分析基础设施层与上层应用层的性能数据,快速判断一个应用卡顿是否由底层虚拟机资源争抢引起,实现了从孤立的设备监控到服务于业务体验的全局监控视角转变。
业务连续性规划(BCP)严重依赖于对系统依赖关系和风险点的准确认知。智慧运维平台中动态生成的应用拓扑图、梳理出的关键业务链路、以及历史故障影响范围分析,为制定准确的BCP提供了较真实的数据基础。平台可以模拟不同灾难场景(如单个AZ故障、数据库宕机)对业务的影响,并验证容灾切换方案的有效性。这使得BCP从一份静态的文档,变成了一个基于实时系统状态、可数据化验证的动态管理过程。没有一个平台能解决所有问题,因此智慧运维平台的生态与集成能力至关重要。良好的平台应提供丰富的API、SDK和插件机制,能够轻松与现有的ITSM、CMDB、自动化工具、通信平台(如Slack、钉钉)以及云服务商的原生监控服务集成。通过构建一个开放的生态系统,智慧运维平台可以成为运维工具链的“指挥中心”,聚合各方数据与能力,而不必替代所有工具,从而以更灵活、更低成本的方式创造价值。针对园区安防设备,智慧运维平台可采集运行数据,分析设备工作状态。
现代智慧运维平台早已超越了技术基础设施的监控,其后面目标是保障并优化较终的用户体验和业务价值。因此,它引入了业务拓扑和用户体验监控的概念。平台能够将底层的技术指标(如应用响应时间、数据库查询延迟)与顶层的业务关键绩效指标(如订单成功率、支付交易量、用户活跃度)进行动态关联映射。当业务指标出现下滑时,运维和业务团队可以快速下钻,定位到是哪个应用、哪个服务、甚至是哪段代码导致了问题。同时,通过真实用户监控和合成监控,平台能够从终端用户的视角,持续度量Web页面加载速度、移动App的卡顿情况、API调用的成功率等,准确刻画用户体验。这使得运维工作与公司主要业务目标紧密对齐,运维团队的贡献不再只只是“保证服务器不死”,而是直接转化为“保障收入稳定”和“提升客户满意度”,实现了从成本中心向价值中心的重要转变。智慧运维平台助力建筑企业构建一体化的建筑设备运维管理体系。吉林智慧运维平台收费
智慧运维平台具备数据采集功能,可实时捕捉设备的运行状态信息。实时监测智慧运维平台批发
在现代应用性能管理(APM)中,智慧运维平台通过嵌入应用的探针,采集从用户端到服务端全链路的深度数据。它不仅能展示应用的响应时间、错误率,更能通过代码级追踪,将性能瓶颈定位到具体的数据库查询、第三方API调用或某行低效代码。平台利用机器学习对应用依赖关系进行动态发现和建模,当某个微服务性能下降时,能清晰展示出其“下游”影响的所有服务。这种深度洞察使得开发与运维团队拥有了共同的语言,能够快速协作,持续优化用户体验。实时监测智慧运维平台批发