商机详情 -
创新上讯数据网关包含
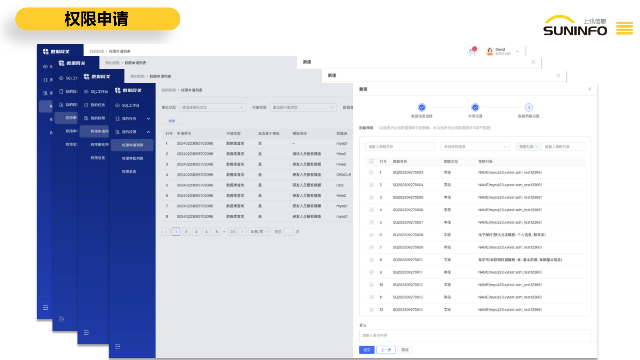
数据库数量多,缺少集中的管理入口:随着企业规模的扩大和业务的增长,数据库数量呈现爆炸式增长,但往往缺乏一个集中的管理入口,导致数据库分散管理、信息孤岛现象严重。不同数据库可能使用不同的管理工具或系统,给数据库管理人员带来了繁琐的管理任务和操作成本。因此,企业急需一个集中的数据库管理平台,实现对所有数据库的统一管理和监控。上海上讯信息技术股份有限公司自主研发的数据网关DG通过对数据库操作人员的细颗粒度权限管控、敏感数据动态脱敏、SQL审核、高危操作管控等,实现运维过程中的事前预防、事中管控和事后审计,为数据库管理者提供简单高效的数据管控解决方案,满足内部数据安全保护需求和外部监管要求.
数据网关DG支持高可用部署,确保系统在高负载和异常情况下依然保持稳定运行。创新上讯数据网关包含
数据雷达提供了多种分类分级算法,包括AI大模型算法、正则算法、字典算法和应用算法,旨在满足用户不同的分类需求,提高数据分类的准确性和效率。正则算法:(1)自定义正则:用户可以通过编写正则算法来对数据进行分类分级,根据自身业务需求,灵活定义匹配规则,实现数据的准确分类。(2)多字段打标支持:支持多字段方式,用户可以针对多个字段进行正则匹配,并根据匹配结果对数据的级别和类别进行打标,实现更加精细化的数据分类。(3)多算法配置:用户可同时配置多个正则算法进行逻辑操作,包括与、或、非等功能。通过组合不同的正则算法,可以实现更复杂的数据分类逻辑,提升分类准确性和灵活性。智能任务调度上讯数据网关产品支持数据库客户端的操作录像。
数据分类分级落地面临的挑战,传统的数据分类分级技术无法满足快速增长的大规模数据的需求。词法分析的局限性导致数据分类分级的准确度较低,基于字段名称和注释的分类分级规则可复制性比较差,数据分类分级规则的编写和维护需要大量人力介入。上讯数据雷达,基于AI的智能数据分类分级工具。基于数据字段内容的模型训练,保证了数据分类分级模型的可复制性基于AI大模型,通过针对数据字段的内容进行训练,在不依靠数据字段的名称和注释的情况下就能够达到很高的准确度,所以保证了训练后的数据分类分级模型的可复制性,可以应用在***的数据环境下。
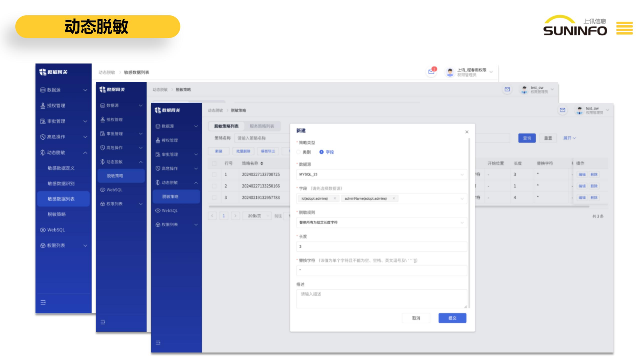
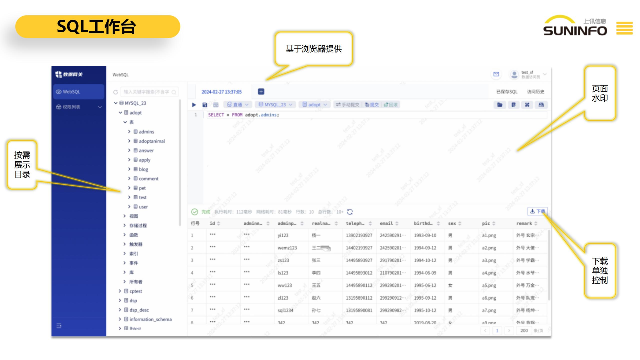
数据网关DG提供虚拟的数据访问功能,通过字段级别的权限划分和细颗粒度的权限管控,确保对访问数据源的用户进行有效的权限管理,保障数据的安全和隐私。查询大表控制:数据网关DG能够有效地控制对大表的查询结果集访问条数,优化查询性能,确保系统稳定运行。提供内置的SQL工作台,通过浏览器Web页面对数据库进行操作。用户可以通过友好的图形化界面进行数据库查询、修改、管理等操作,无需额外的客户端软件,增强了用户操作的灵活性和便利性。客户端和工具支持:通过使用数据网关的JDBC驱动,用户可以在数据库客户端(如DBeaver、Datagrip)和BI分析工具(如SmartBI、帆软Report)中进行数据库操作,拓展了数据访问和分析的应用场景。
上讯数据网关 DG 具备强大的安全防护功能,有效抵御外部网络攻击,保护企业核心数据。
数据雷达提供了多种分类分级算法,包括AI大模型算法、正则算法、字典算法和应用算法,旨在满足用户不同的分类需求,提高数据分类的准确性和效率。自定义算法分组:通过自定义算法分组,用户可以根据算法的功能、用途或者行业领域等因素进行分类,将具有相似特性或者功能的算法归类到同一个分组下。这样一来,用户可以更快速地找到需要的算法,同时也可以更清晰地了解系统中各个算法的分类和属性。分类分级算法共享:所有用户均可在分类分级算法组织架构下共享这些算法,提升了协作效率和资源利用率。数据分类分级算法能够为企业提供高效、准确的数据分类和分级服务,帮助企业更好地管理和保护数据资产,降低数据泄露和滥用的风险,提升数据安全性和合规性水平,增强企业对数据的控制能力,从而提升企业的运营效率和竞争力。上讯数据网关DG能够解决企业在数据库访问过程存在的安全和合规风险。什么是上讯数据网关商家
上讯数据网关产品基于浏览器的客户端,部署管理更简单,使用更安全。创新上讯数据网关包含
数据雷达(DR)是基于AI大模型技术的智能数据分类分级产品,能够针对关系性数据库、NoSQL数据库和数据仓库等实现元数据扫描、数据目录构建、分类分级模型训练和自动化识别。相比于传统的数据分类分级产品,数据雷达产品具有如下优势:结果更准确基于AI大模型,能够实现同时针对数据类型在词法、语法和语义级别的特征提取和分析,从而针对数据类型建立语义级别的高纬度特征向量,**提高了数据分类分级的准确度。可复制性更好基于AI大模型,通过针对数据字段的内容进行训练,在不依靠数据字段的名称和注释的情况下就能够达到很高的准确度,所以保证了训练后的数据分类分级模型的可复制性。扩展性更好基于AI大模型,使用人员只需要针对一个数据类型准备几千条-几万条的训练数据就可以实现数据类型识别能力的训练,不需要针对不同的数据类型编写和维护。创新上讯数据网关包含